 BroRL: Scaling Reinforcement Learning via Broadened Exploration.
BroRL: Scaling Reinforcement Learning via Broadened Exploration.
Jian Hu, Mingjie Liu, Ximing Lu, Fang Wu, Zaid Harchaoui, Shizhe Diao, Yejin Choi, Pavlo Molchanov, Jun Yang, Jan Kautz, Yi Dong†
Under Review
[Paper]
[Model]
 DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search.
DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search.

Fang Wu*, Weihao Xuan*, Heli Qi*, Ximing Lu, Aaron Tu, Li Erran Li, Yejin Choi†
ICLR 2026
🥇 #1 of the Day
[Paper]
[Code]
[Model]
 Multiplayer Nash Preference Optimization.
Multiplayer Nash Preference Optimization.

Fang Wu*, Xu Huang*, Weihao Xuan, Zhiwei Zhang, Yijia Xiao, Guancheng Wan, Xiaomin Li, Bing Hu, Peng Xia, Jure Leskovec, Yejin Choi†
ICLR 2026 (oral)
🥉 #3 of the Day
[Paper]
[Code]
 The Invisible Leash: Why RLVR May Not Escape Its Origin.
The Invisible Leash: Why RLVR May Not Escape Its Origin.
Fang Wu*, Weihao Xuan*, Ximing Lu, Zaid Harchaoui, Yejin Choi†
Under Review
🥉 #3 of the Day
[Paper]
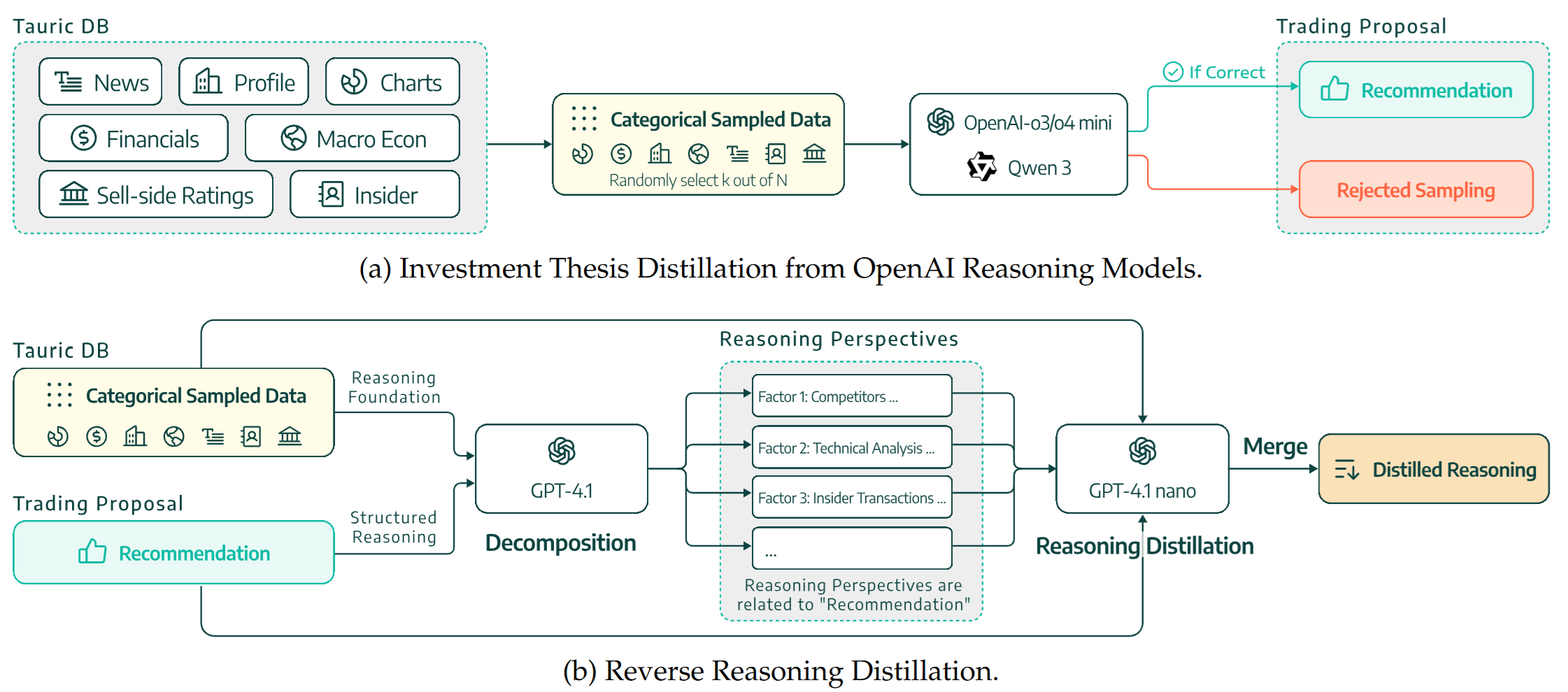 Trading-R1: Financial Trading with LLM Reasoning via Reinforcement Learning.
Trading-R1: Financial Trading with LLM Reasoning via Reinforcement Learning.

Yijia Xiao, Edward Sun, Tong Chen, Fang Wu, Di Luo, Wei Wang†
Under Review
[Paper]
[Code]
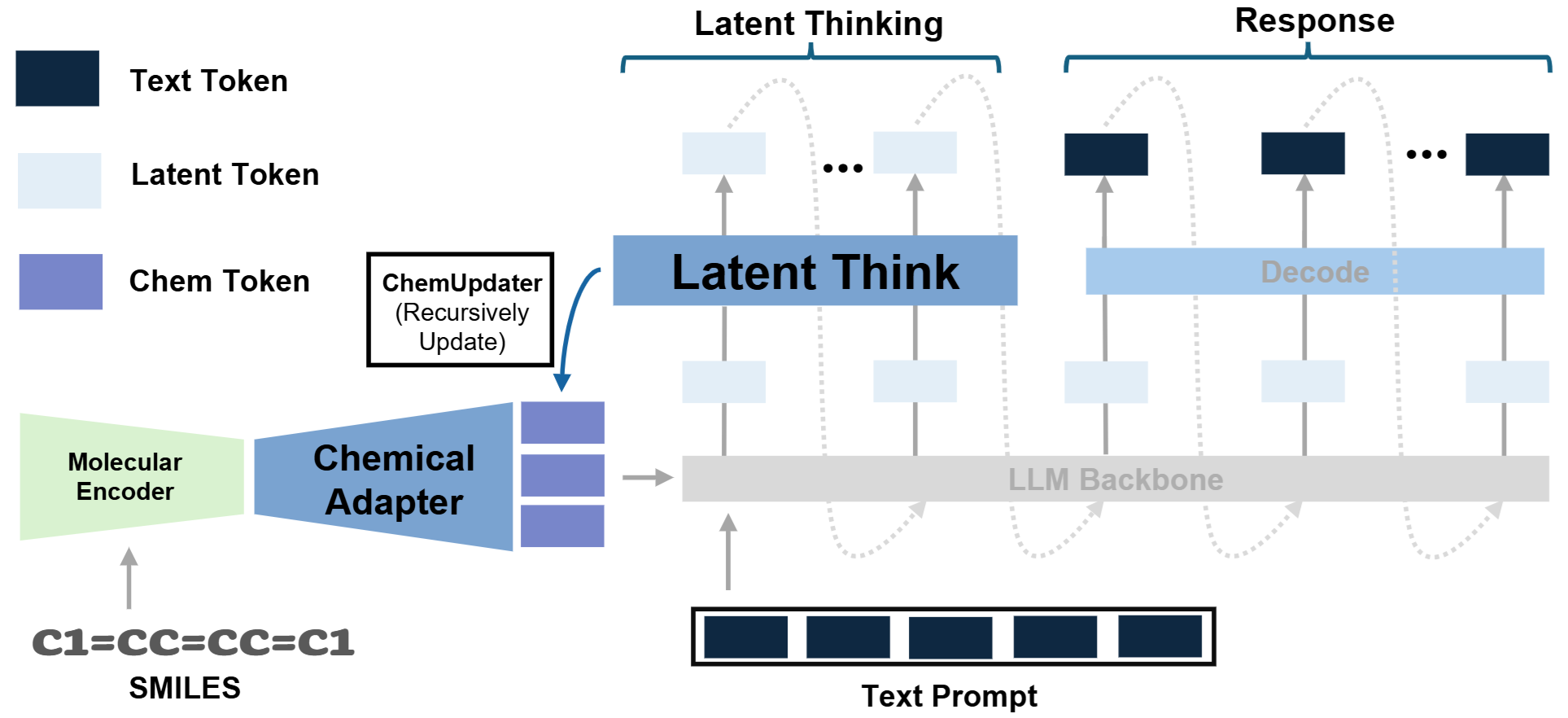 LatentChem: From Textual CoT to Latent Thinking in Chemical Reasoning.
LatentChem: From Textual CoT to Latent Thinking in Chemical Reasoning.

Xinwu Ye, Yicheng Mao, Jia Zhang, Yimeng Liu, Li Hao, Fang Wu, Zhiwei Li, Yuxuan Liao, Zehong Wang, Zhiyuan Liu, Zhenfei Yin, Li Yuan, Philip Torr, Huan Sun, Xiangxiang Zeng, Mengdi Wang, Le Cong, Shenghua Gao, Xiangru Tang†
Under Review
[Paper]
[Code]
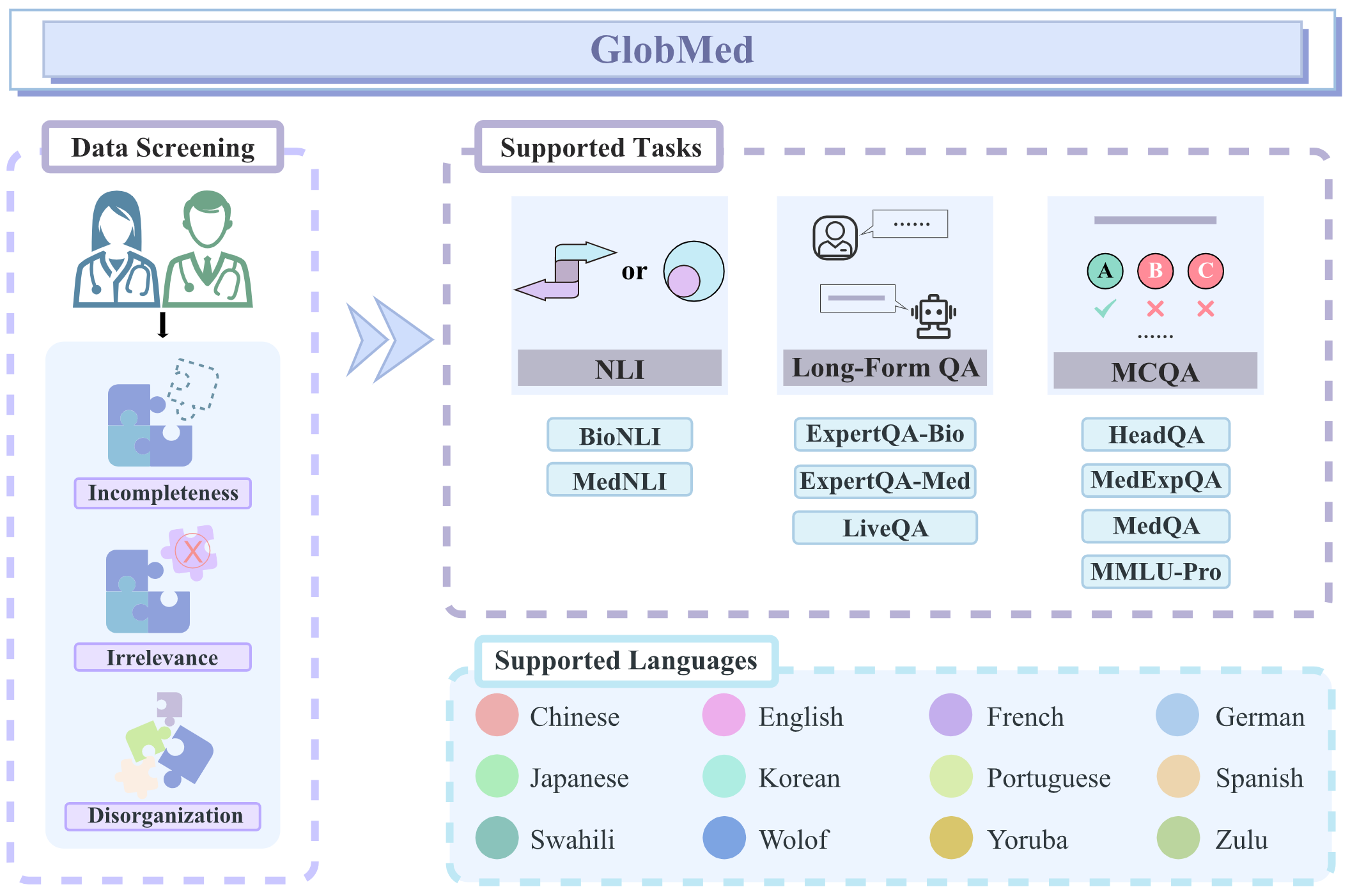 Toward Global Large Language Models in Medicine.
Toward Global Large Language Models in Medicine.

GlobMed Team
Under Review
[Paper]
[Code]
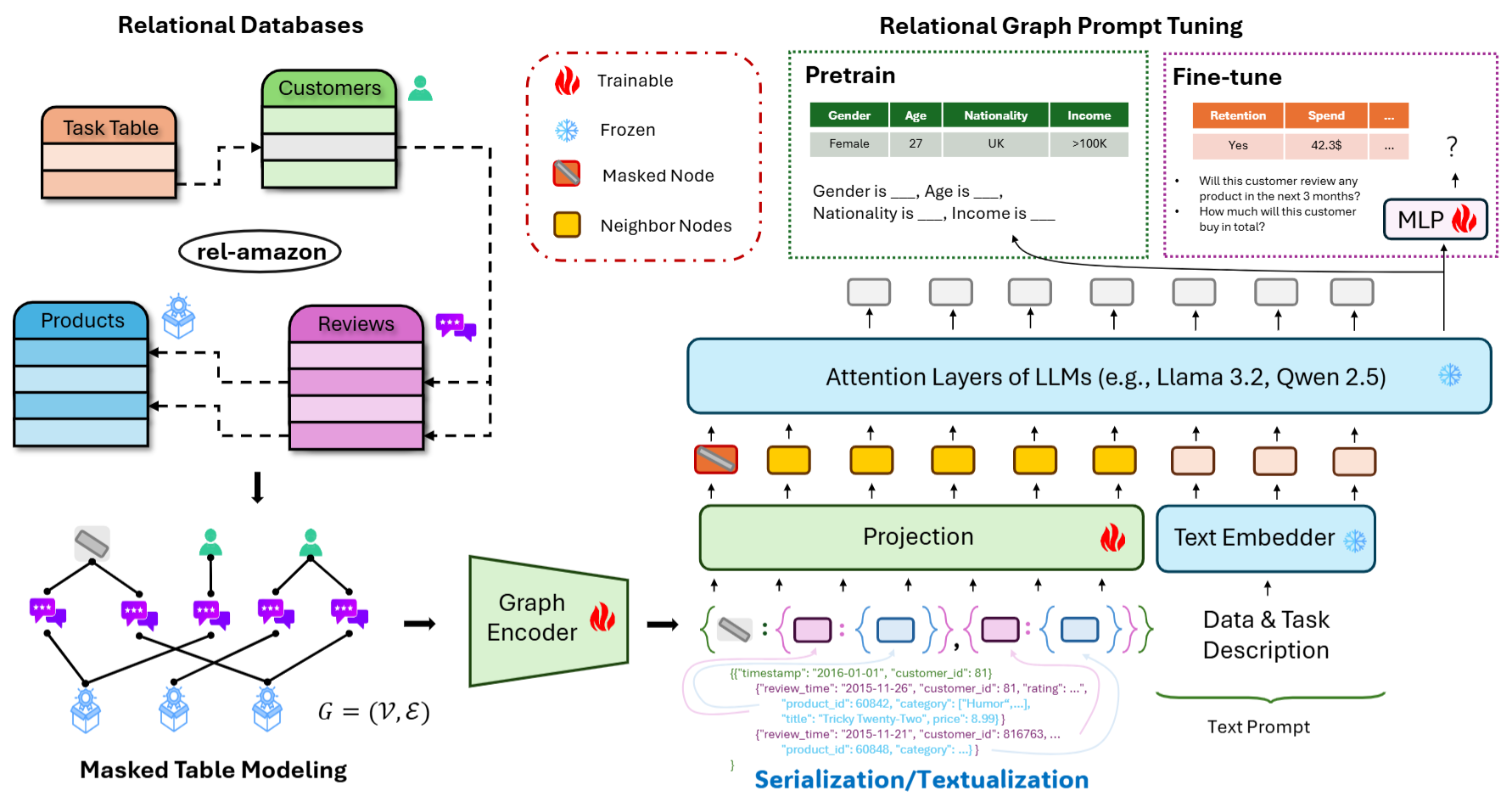 Large Language Models are Good Relational Learners.
Large Language Models are Good Relational Learners.

Fang Wu, Vijay Prakash Dwivedi, Jure Leskovec†
ACL 2025
[Paper]
[Code]
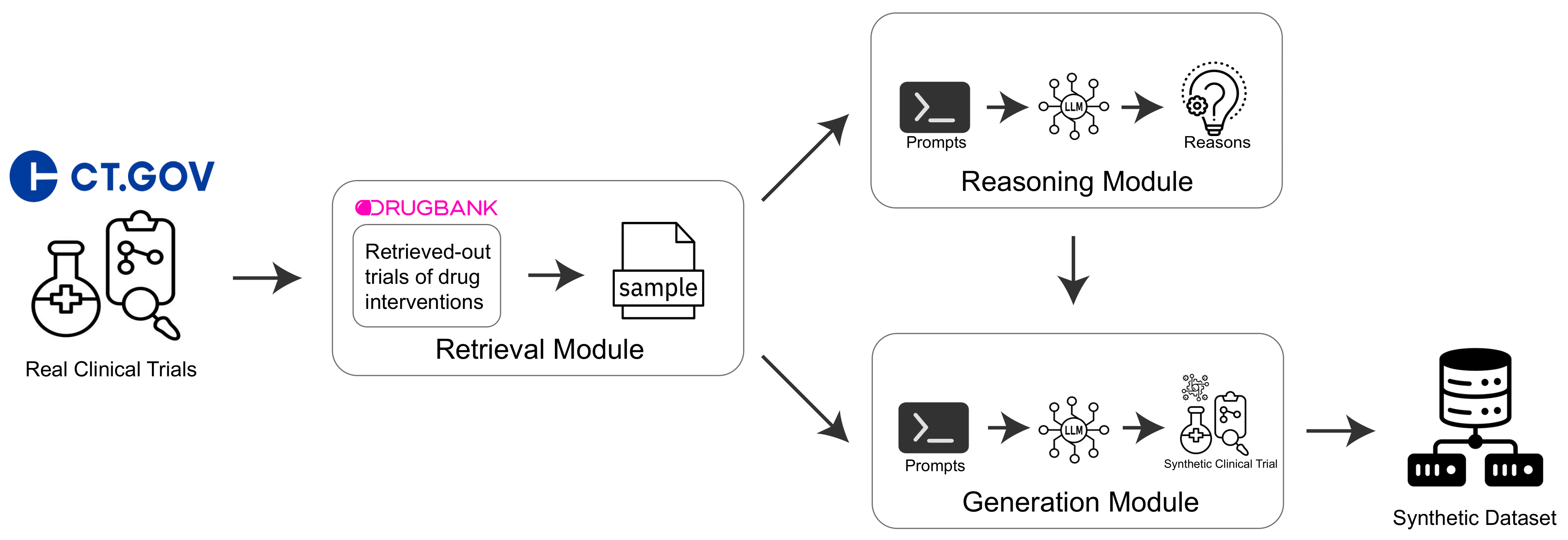 Retrieval-Reasoning Large Language Model-based Synthetic Clinical Trial Generation
Retrieval-Reasoning Large Language Model-based Synthetic Clinical Trial Generation

Zerui Xu, Fang Wu, Tianfan Fu, Yue Zhao†
ACM BCB 2025
[Paper]
[Code]
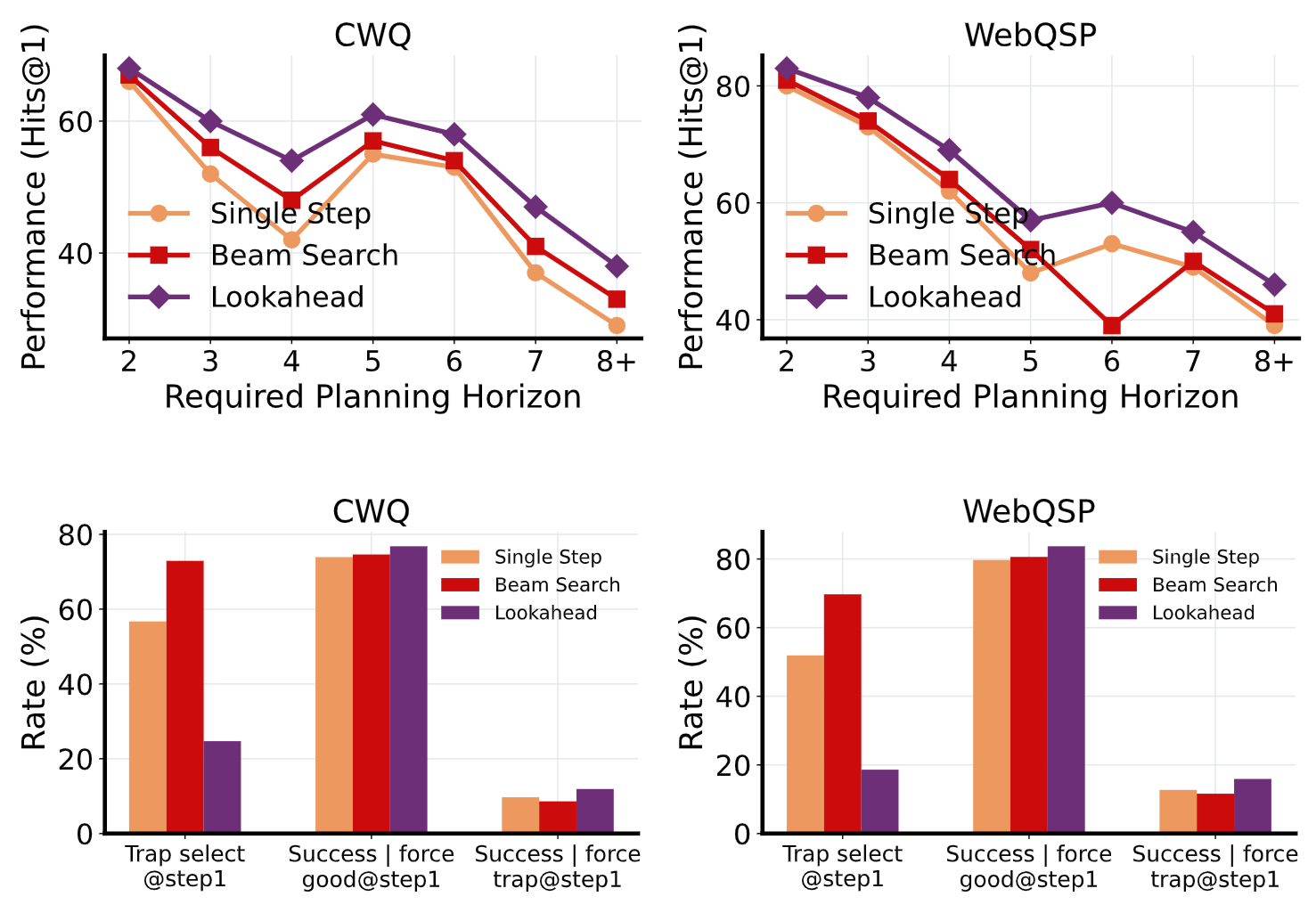 Why Reasoning Fails to Plan: A Planning-Centric Analysis of Long-Horizon Decision Making in LLM Agents
Why Reasoning Fails to Plan: A Planning-Centric Analysis of Long-Horizon Decision Making in LLM Agents

Zehong Wang, Fang Wu, Hongru Wang, Xiangru Tang, Bolian Li, Zhenfei Yin, Yijun Ma, Yiyang Li, Weixiang Sun, Xiusi Chen, Yanfang Ye†
Under Review
[Paper]
[Code]
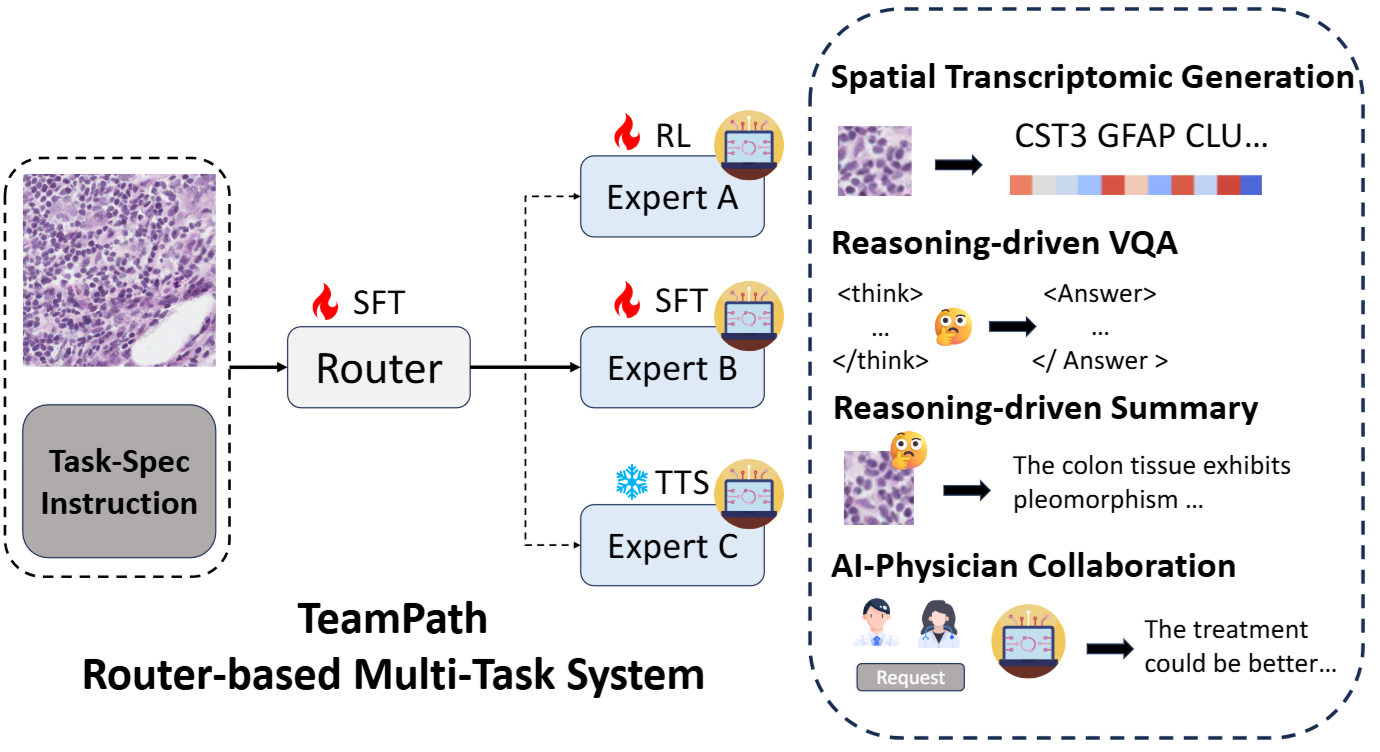 TeamPath: Building MultiModal Pathology Experts with Reasoning AI Copilots
TeamPath: Building MultiModal Pathology Experts with Reasoning AI Copilots
Tianyu Liu*, Weihao Xuan*, Hao Wu, Peter Humphrey, Marcello DiStasio, Heli Qi, Rui Yang, Simeng Han, Tinglin Huang, Fang Wu, Nan Liu, Irene Li, Hua Xu, Hongyu Zhao†
Under Review
[Paper]
[Code]
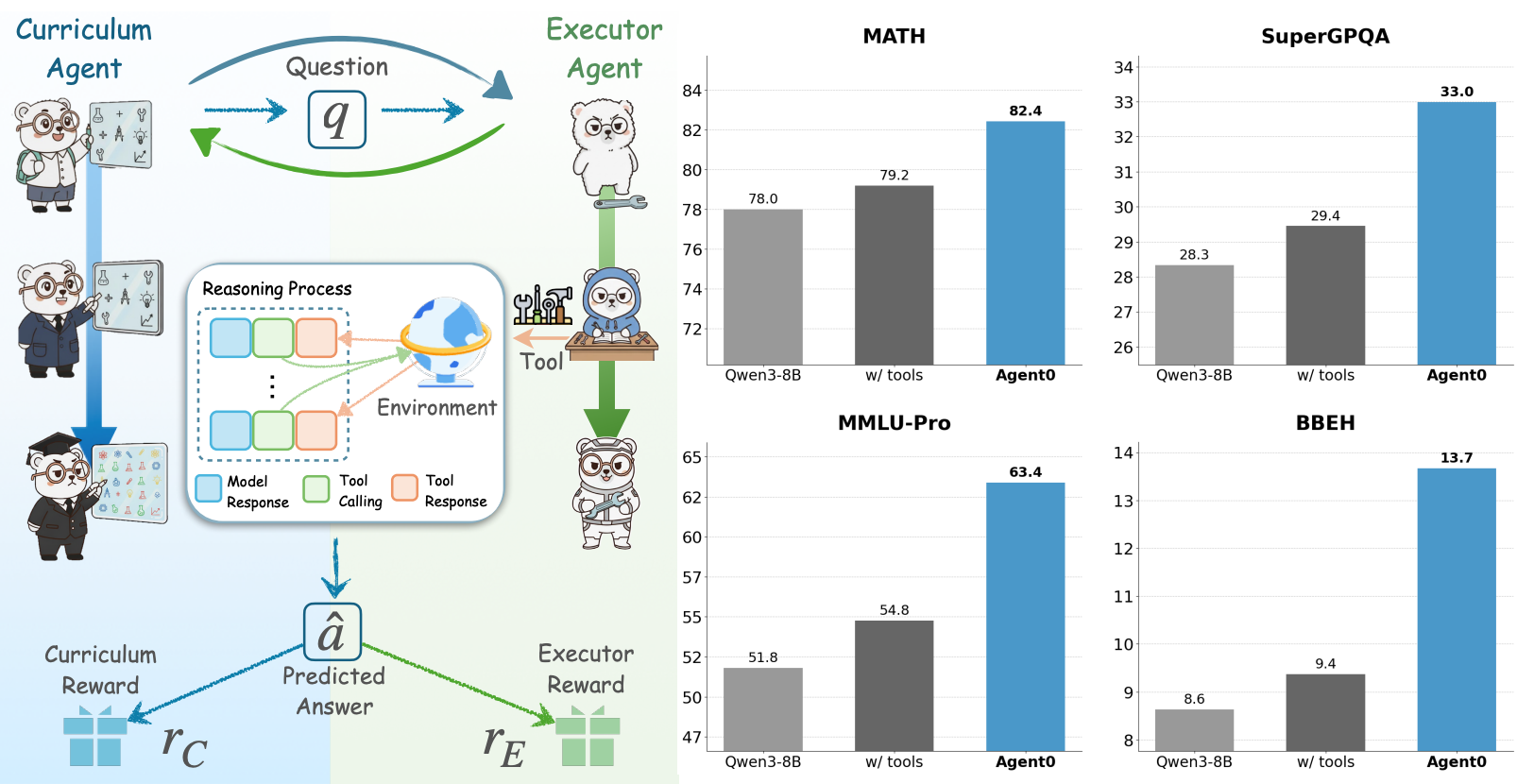 Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning
Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning

Peng Xia, Kaide Zeng, Jiaqi Liu, Can Qin, Fang Wu, Yiyang Zhou, Caiming Xiong, Huaxiu Yao†
Under Review
[Paper]
[Code]
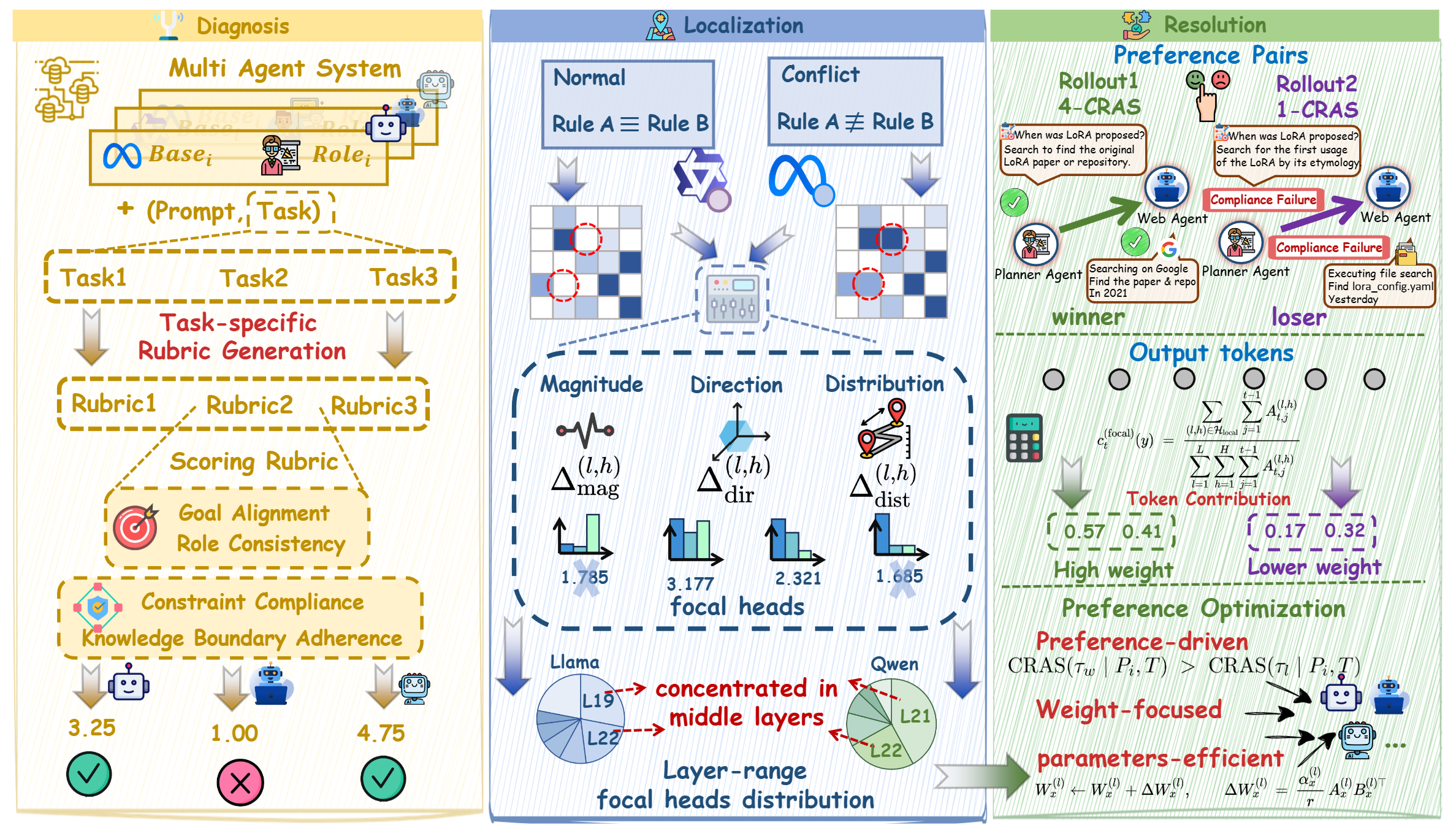 Diagnose, Localize, Align: A Full-Stack Framework for Reliable LLM Multi-Agent Systems under Instruction Conflicts
Diagnose, Localize, Align: A Full-Stack Framework for Reliable LLM Multi-Agent Systems under Instruction Conflicts

Guancheng Wan, Leixin Sun, Longxu Dou, Zitong Shi, Fang Wu, Eric Hanchen Jiang, Wenke Huang, Guibin Zhang, Hejia Geng,
Xiangru Tang, Zhenfei Yin, Yizhou Sun, Wei Wang†
Under Review
[Paper]
[Code]
 When to Trust Context: Agentic Debates for Context Reliability
When to Trust Context: Agentic Debates for Context Reliability

Zeqi Zhou*, Fang Wu*†, Shayan Talaei*, Haokai Zhao, Cheng Meixin, Tinson Xu, Amin Saberi, Yejin Choi
ACL 2025 KnowFM Workshop
[Paper]
[Code]
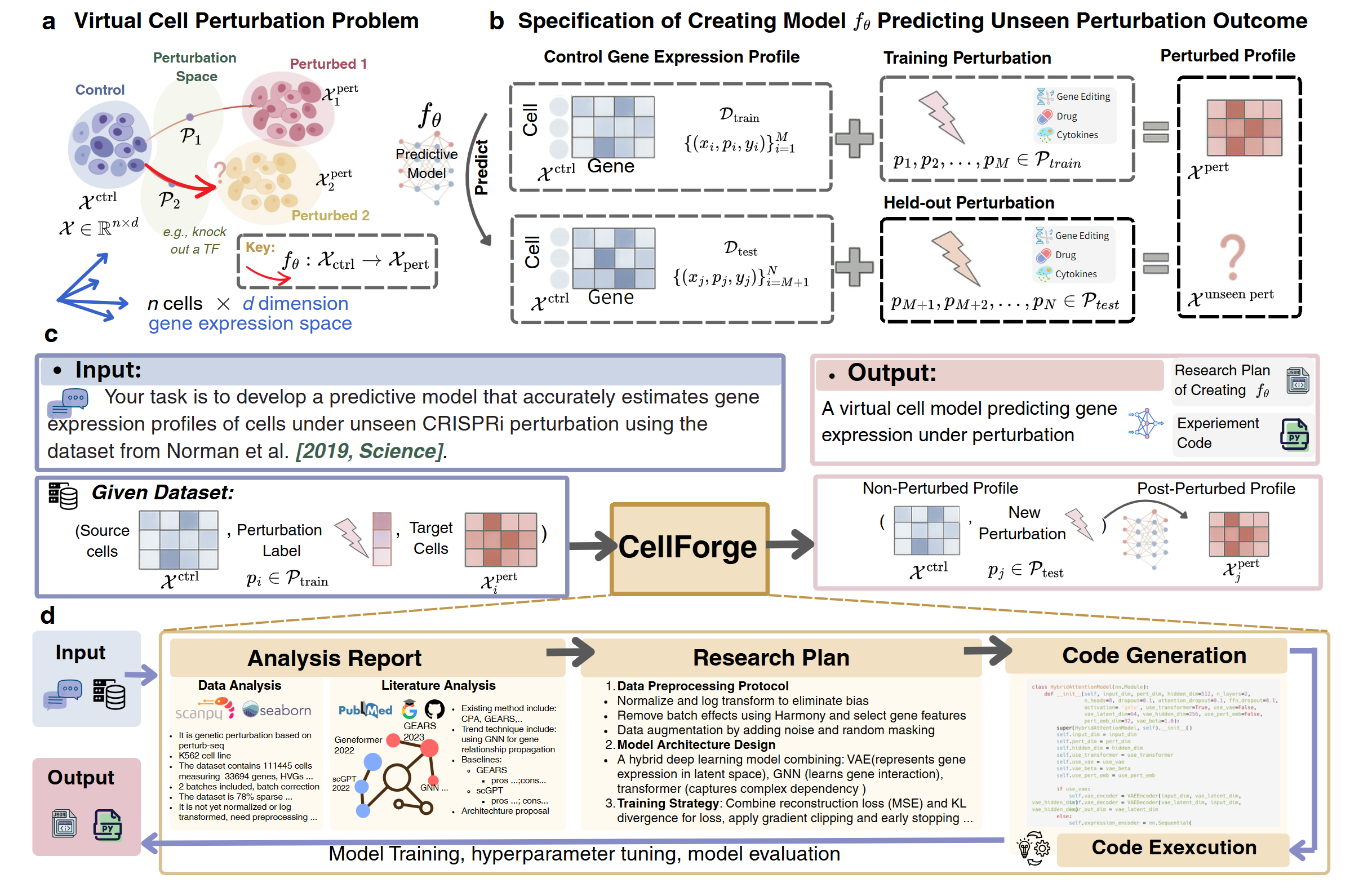 CellForge: Agentic Design of Virtual Cell Models
CellForge: Agentic Design of Virtual Cell Models

Xiangru Tang*, Zhuoyun Yu*, Jiapeng Chen*, Yan Cui, Daniel Shao, Weixu Wang, Fang Wu, Yuchen Zhuang, Wenqi Shi,
Zhi Huang, Arman Cohan, Xihong Lin, Fabian Theis, Smita Krishnaswamy, Mark Gerstein†
Under Review
[Paper]
[Code]
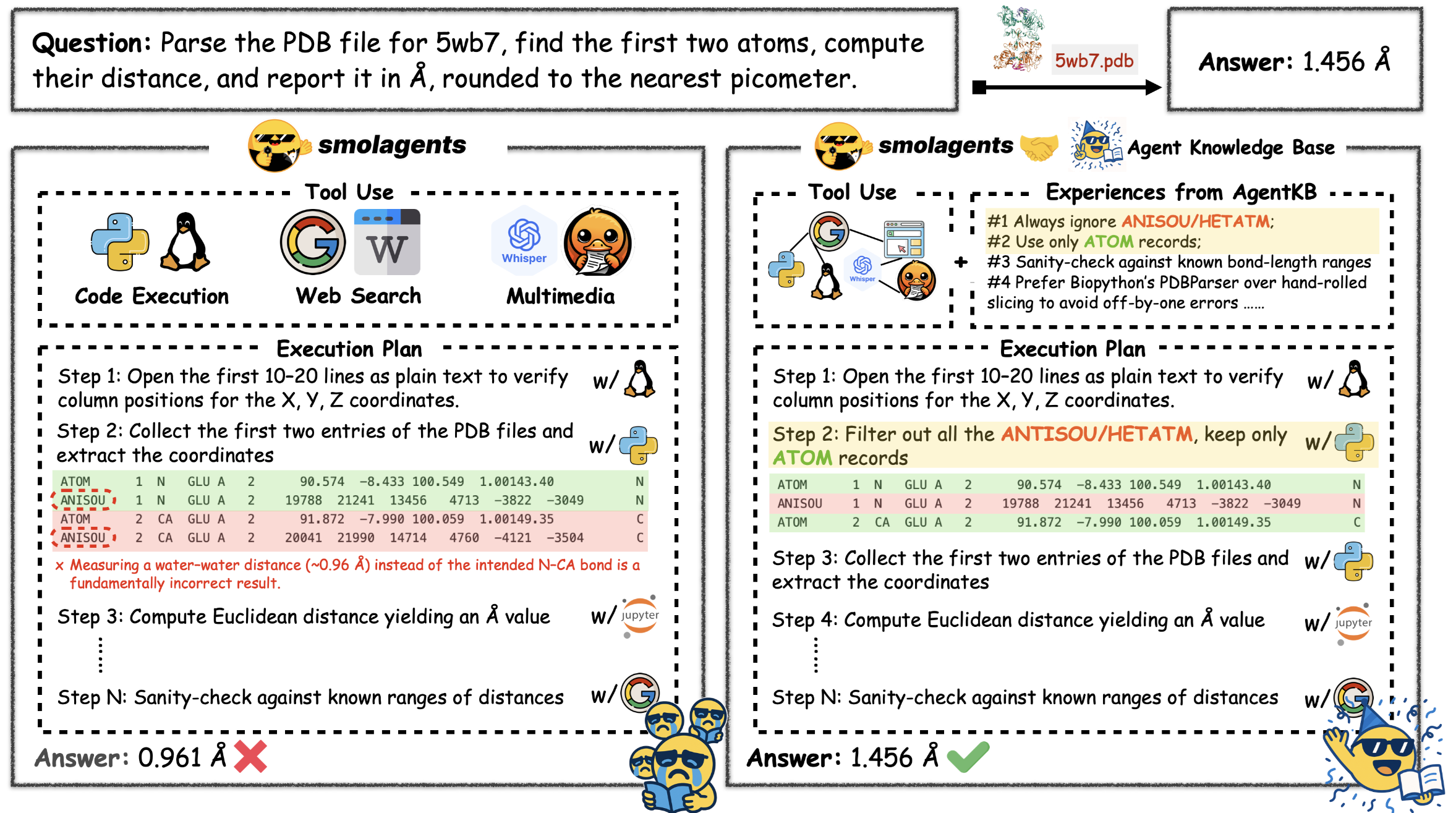 Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving.
Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving.

Xiangru Tang*, Tianrui Qin*, Tianhao Peng*, Ziyang Zhou, Daniel Shao, Tingting Du, Xinming Wei, Peng Xia, Fang Wu, He Zhu, Ge Zhang, Jiaheng Liu,
Xingyao Wang, Sirui Hong, Chenglin Wu, Hao Cheng, Chi Wang, Wangchunshu Zhou†
Under Review
[Paper]
[Code]
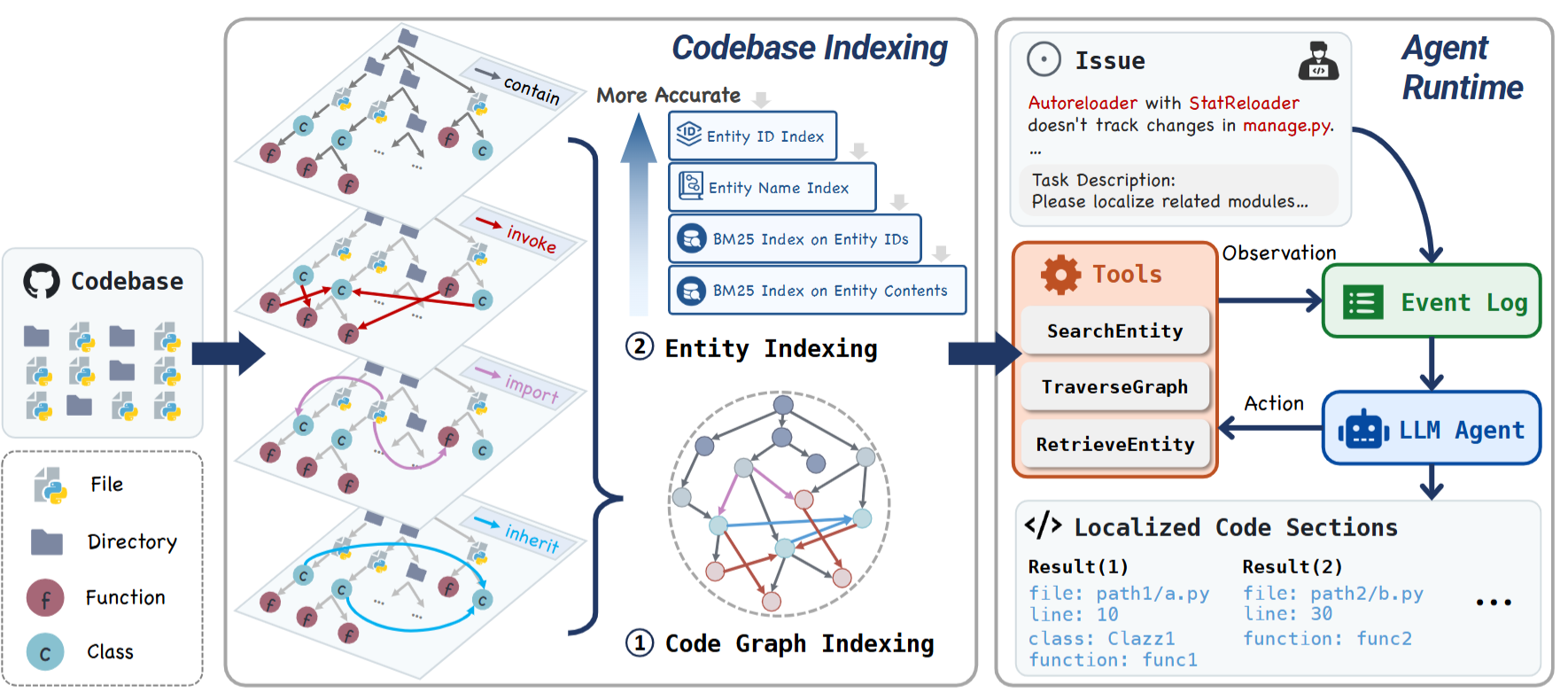 LocAgent: Graph-Guided LLM Agents for Code Localization.
LocAgent: Graph-Guided LLM Agents for Code Localization.

Zhaoling Chen*, Xiangru Tang*, Gangda Deng*, Fang Wu, Jialong Wu, Zhiwei Jiang, Viktor Prasanna, Arman Cohan, Xingyao Wang†
ACL 2025
[Paper]
[Code]
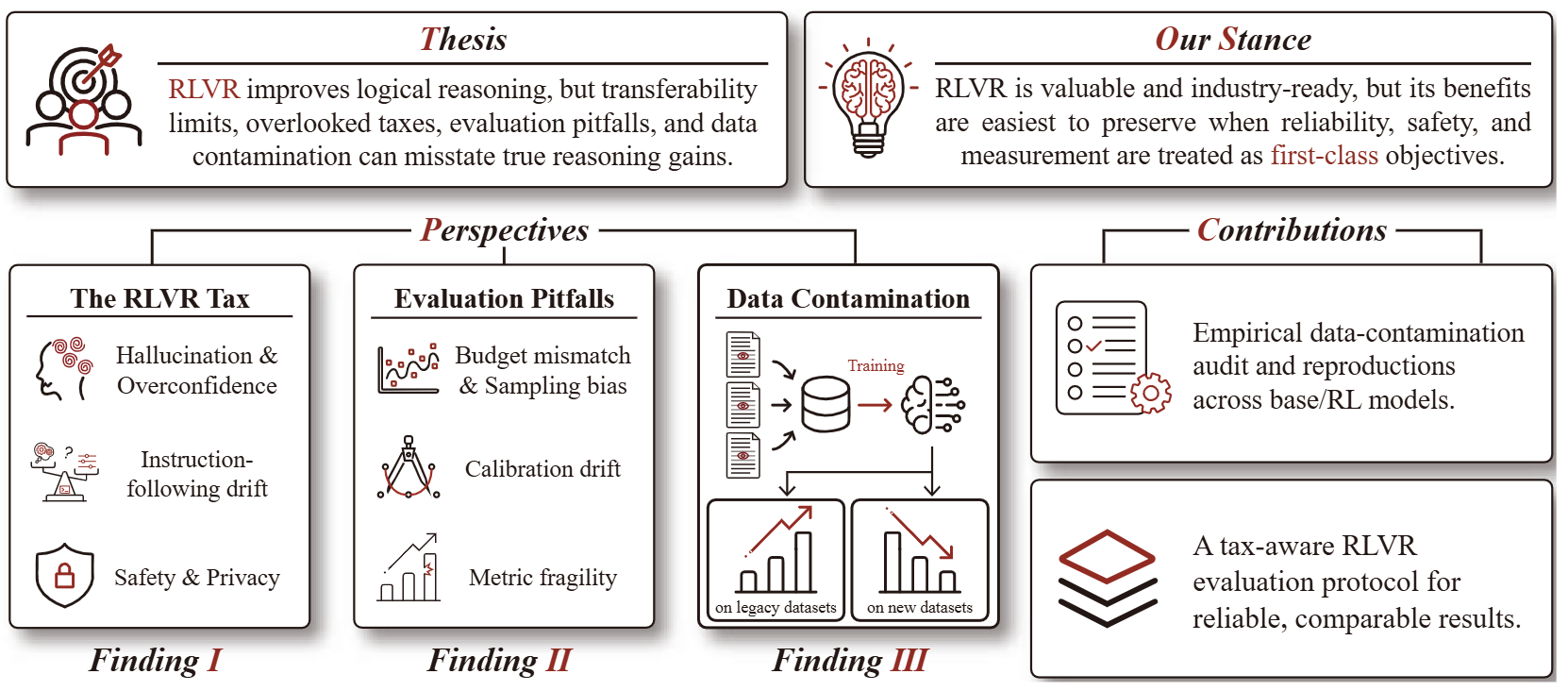 Position: The Hidden Costs and Measurement Gaps of Reinforcement Learning with Verifiable Rewards.
Position: The Hidden Costs and Measurement Gaps of Reinforcement Learning with Verifiable Rewards.
Aaron Tu*, Weihao Xuan*, Heli Qi*, Xu Huang, Qingcheng Zeng, Shayan Talaei, Yijia Xiao, Peng Xia, Xiangru Tang, Yuchen Zhuang, Bing Hu,
Hanqun Cao, Wenqi Shi, Tianang Leng, Rui Yang, Yingjian Chen, Ziqi Wang, Irene Li, Nan Liu, Huaxiu Yao, Li Erran Li, Ge Liu, Amin Saberi,
Naoto Yokoya, Jure Leskovec, Yejin Choi, Fang Wu*†
Under Review
[Paper]
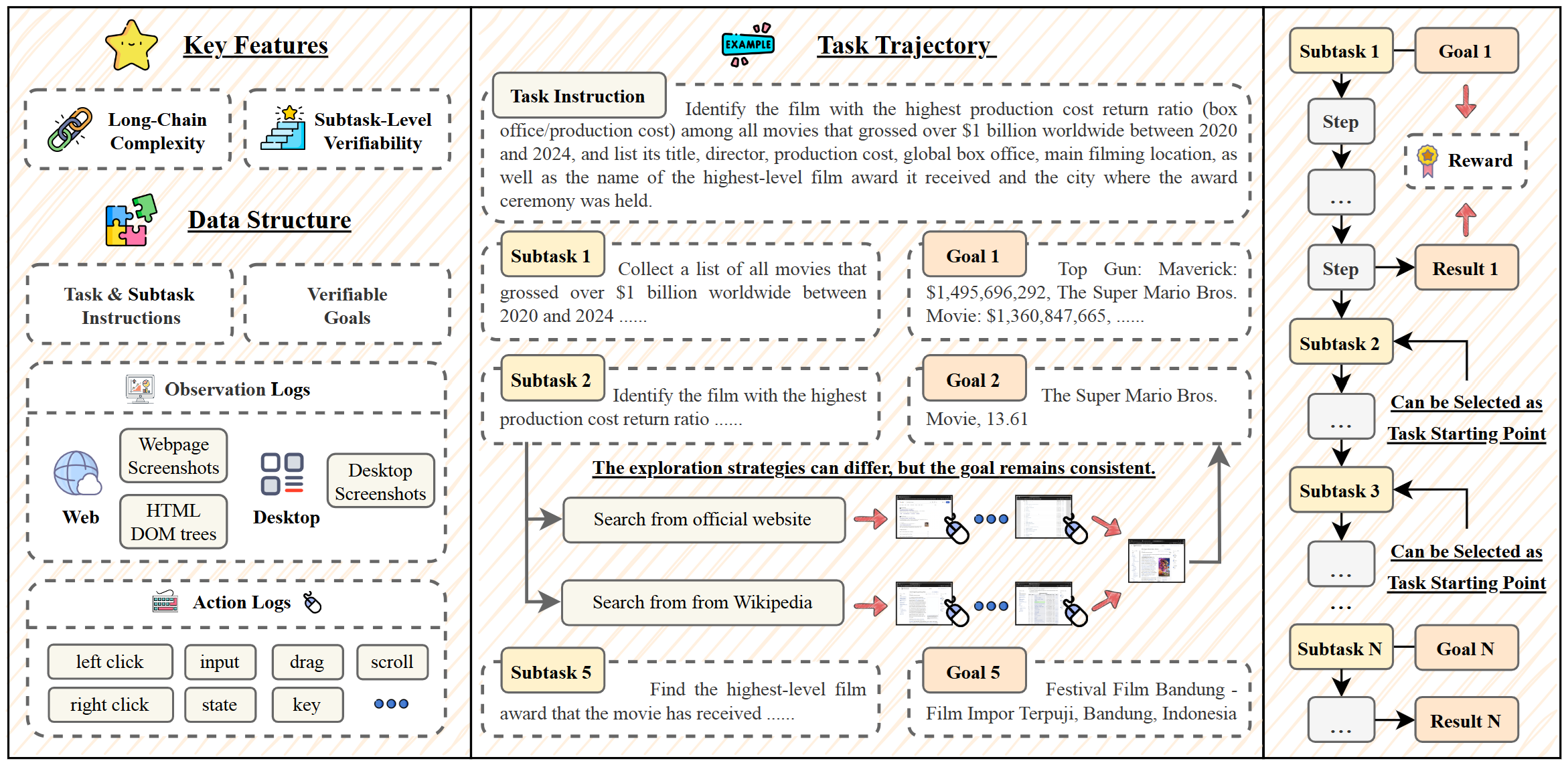 VeriGUI: Verifiable Long-Chain GUI Dataset
VeriGUI: Verifiable Long-Chain GUI Dataset

VeriGUI Team
Under Review
[Paper]
[Code]
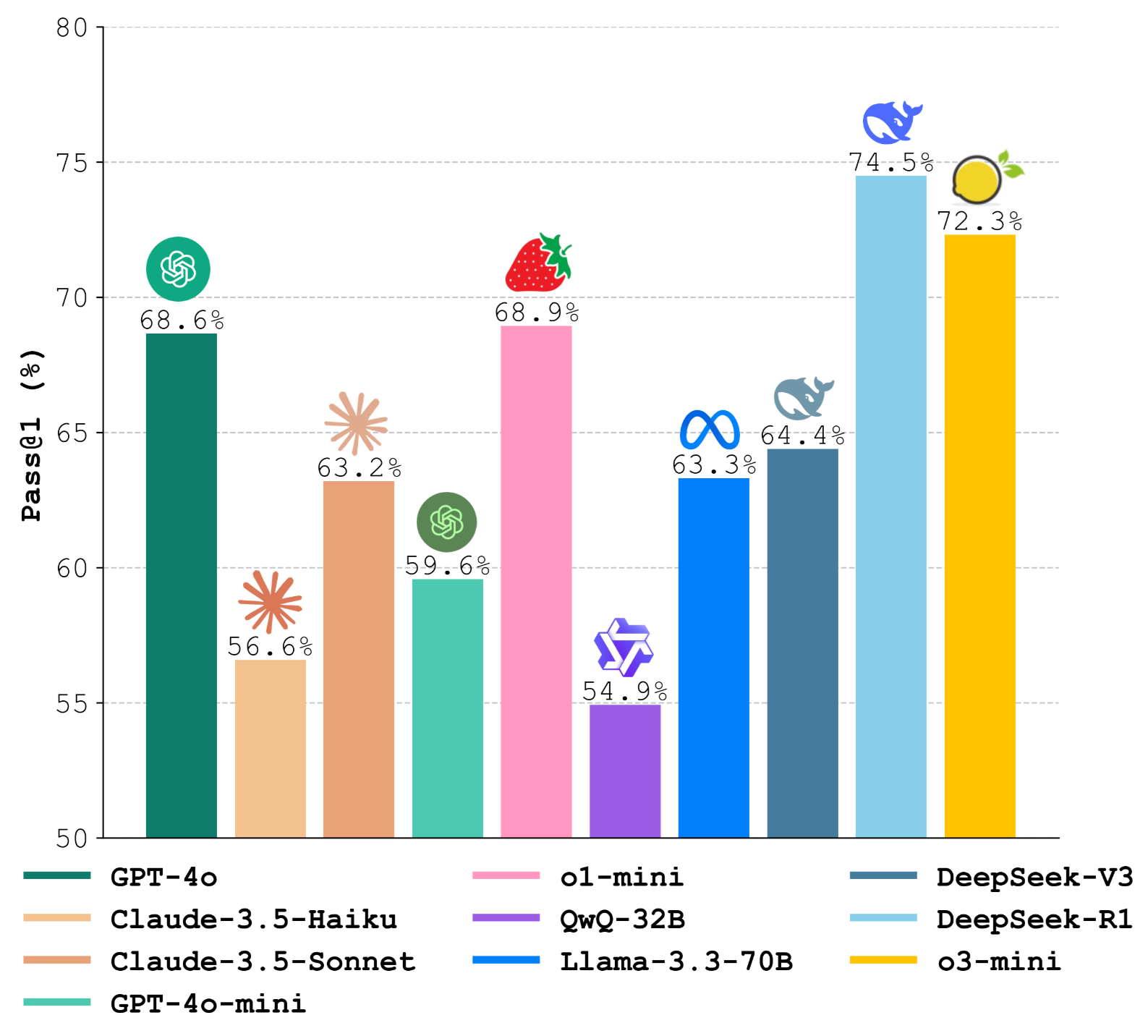 MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning
MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning

Xiangru Tang*, Daniel Shao*, Jiwoong Sohn*, Jiapeng Chen, Jiayi Zhang, Jinyu Xiang, Fang Wu, Yilun Zhao, Chenglin Wu, Wenqi Shi,
Arman Cohan, Mark Gerstein†
Under Review
[Paper]
[Code]
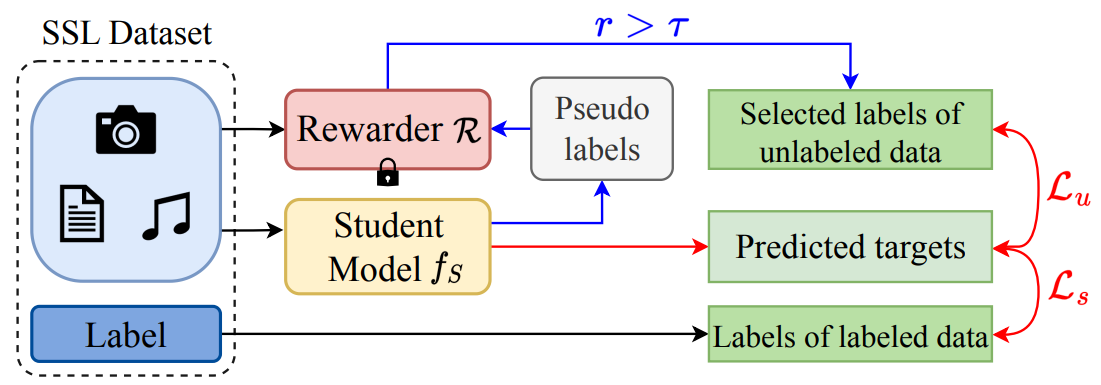 SemiReward: A General Reward Model for Semi-supervised Learning
SemiReward: A General Reward Model for Semi-supervised Learning

Siyuan Li*, Weiyang Jin*, Zedong Wang, Fang Wu,, Zicheng Liu, Cheng Tan, Stan Z. Li†
ICLR 2024
[Paper]
[Code]
 Architecture-Agnostic Masked Image Modeling: From ViT back to CNN
Architecture-Agnostic Masked Image Modeling: From ViT back to CNN

Siyuan Li*, Di Wu*, Fang Wu, Zelin Zang, Kai Wang, Lei Shang, Baigui Sun, Hao Li, Stan Z. Li†
ICML 2023
[Paper]
[Code]